Go 探究
数组
如果数组中元素的个数小于或者等于 4 个,那么所有的变量会直接在栈上初始化,如果数组元素大于 4 个,变量就会在静态存储区初始化然后拷贝到栈上。 为什么?
slice
[]int
[]interface{}
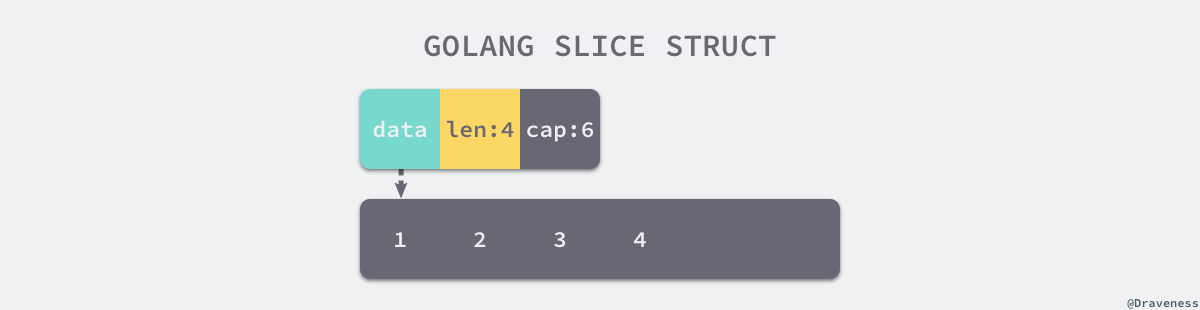
切片提供了对数组中部分连续片段的引用,而作为数组的引用,我们可以在运行区间可以修改它的长度和范围。当切片底层的数组长度不足时就会触发扩容,切片指向的数组可能会发生变化,不过在上层看来切片是没有变化的,上层只需要与切片打交道不需要关心数组的变化。
追加和扩容
- 先确定切片大致容量
- 如果期望容量大于当前容量的两倍就会使用期望容量;
- 如果当前切片的长度小于 1024 就会将容量翻倍;
- 如果当前切片的长度大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
- 再根据切片中的元素大小对齐内存
切片拷贝
无论是编译期间拷贝还是运行时拷贝,两种拷贝方式都会通过 runtime.memmove 将整块内存的内容拷贝到目标的内存区域中:
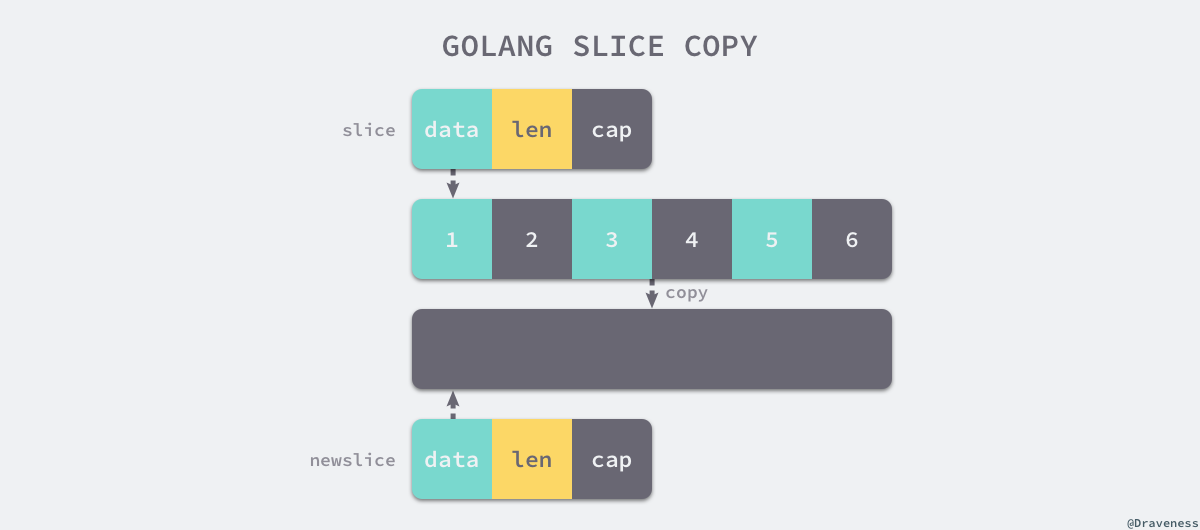
大切片扩容或者复制时可能会发生大规模的内存拷贝,要注意。
map
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
type mapextra struct {
overflow *[]*bmap
oldoverflow *[]*bmap
nextOverflow *bmap
}
- count 表示当前哈希表中的元素数量;
- B 表示当前哈希表持有的 buckets 数量,但是因为哈希表中桶的数量都 2 的倍数,所以该字段会存储对数,也就是 len(buckets) == 2^B;
- hash0 是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入;
- oldbuckets 是哈希在扩容时用于保存之前 buckets 的字段,它的大小是当前 buckets 的一半;
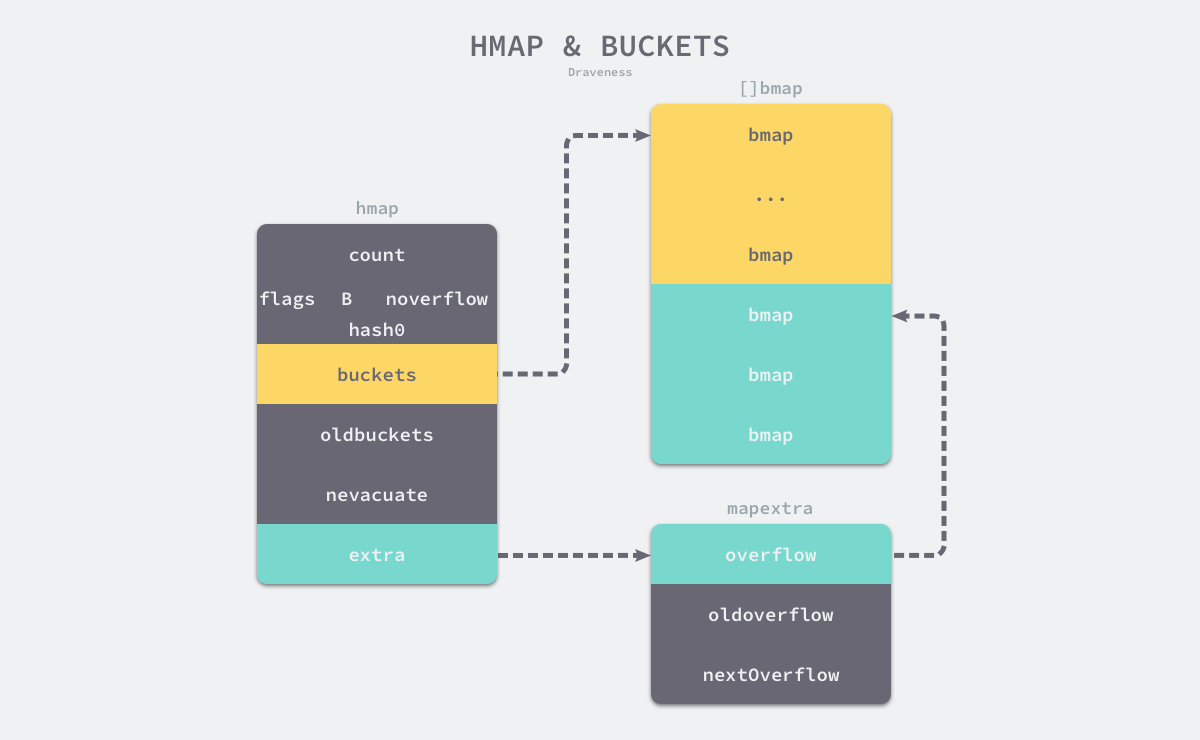
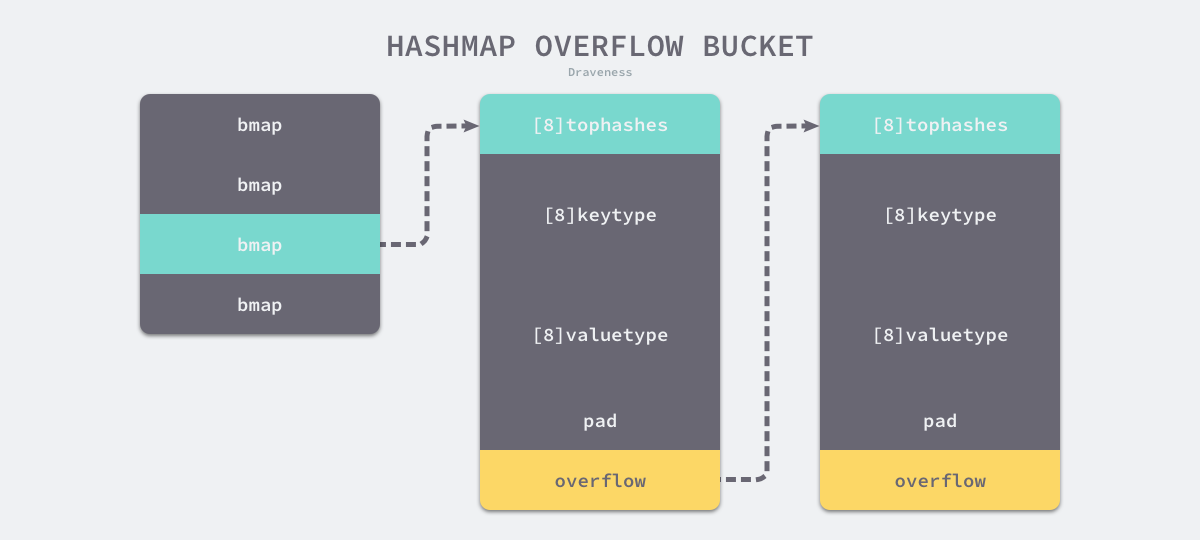
如上图所示哈希表 runtime.hmap 的桶是 runtime.bmap。每一个 runtime.bmap 都能存储 8 个键值对,当哈希表中存储的数据过多,单个桶已经装满时就会使用 extra.nextOverflow 这个bmap 存储溢出的数据。
type bmap struct {
topbits [8]uint8
// 以下字段在运行时也是通过计算内存地址的方式访问的
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
map 初始化
- 字面量
- 当哈希表中的元素数量少于或者等于 25 个时:
hash := make(map[string]int, 3) hash["1"] = 2 hash["3"] = 4 hash["5"] = 6- 元素的数量超过了 25 个: 编译器会创建两个数组分别存储键和值,这些键值对会通过 for 循环加入哈希:
- 运行时
- 当创建的哈希被分配到栈上并且其容量小于 BUCKETSIZE = 8 时,Go 语言在编译阶段会快速初始化哈希,这也是编译器对小容量的哈希做的优化
- 除此之外,只要我们使用 make 创建哈希,最后都调用了 runtime.makemap:
- 计算哈希占用的内存是否溢出或者超出能分配的最大值;
- 调用 runtime.fastrand 获取一个随机的哈希种子;
- 根据传入的 hint 计算出需要的最小需要的桶的数量;
- 使用 runtime.makeBucketArray 创建用于保存桶的数组: 当桶的数量小于 2^4 时不创建溢出桶;否则创建 2^(B-4) 个溢出桶。(正常桶和溢出桶在内存中的存储空间是连续的)
map 读写
- 读:
用于选择桶序号的是哈希的最低几位,而用于加速访问的是哈希的高 8 位,这种设计能够减少同一个桶中有大量相等 tophash 的概率影响性能。
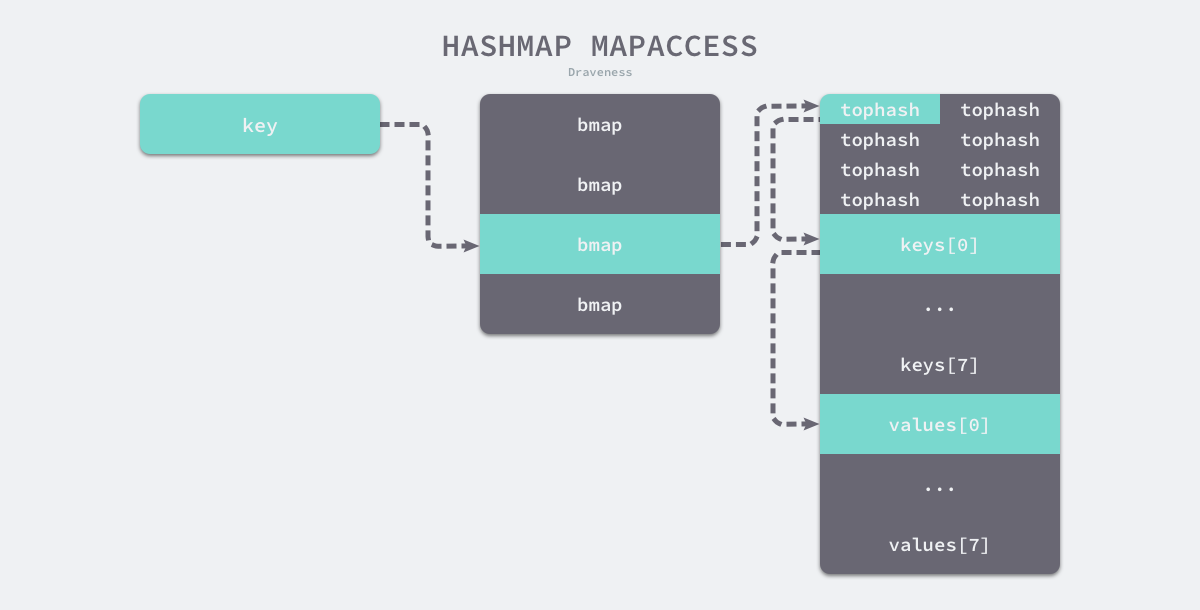 注意:哈希表扩容并不是原子过程
注意:哈希表扩容并不是原子过程 - 写:
- 如果当前桶已经满了,哈希会调用 runtime.hmap.newoverflow 创建新桶或者使用 runtime.hmap 预先在 noverflow 中创建好的桶来保存数据,新创建的桶不仅会被追加到已有桶的末尾,还会增加哈希表的 noverflow 计数器。
- 如果当前键值对在哈希中不存在,哈希会为新键值对规划存储的内存地址
扩容
runtime.mapassign 函数会在以下两种情况发生时触发哈希的扩容:
- 装载因子已经超过 6.5;
- 哈希使用了太多溢出桶;
根据触发的条件不同扩容的方式分成两种,如果这次扩容是溢出的桶太多导致的,那么这次扩容就是等量扩容 sameSizeGrow, 通过复用已有的哈希扩容机制解决缓慢的内存泄露问题,一旦哈希中出现了过多的溢出桶,它会创建新桶保存数据,垃圾回收会清理老的溢出桶并释放内存。
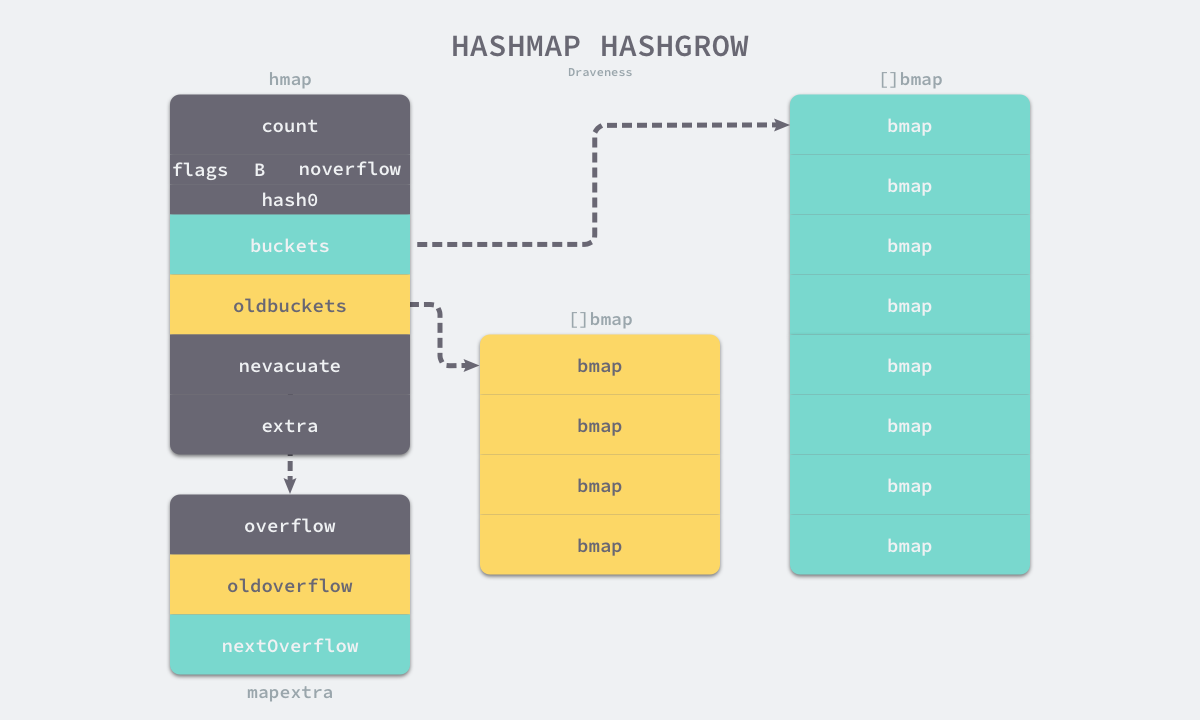
- 扩容期间获取键值对的逻辑: 当哈希表的 oldbuckets 存在时,会先定位到旧桶并在该桶没有被分流时从中获取键值对。
- 扩容期间写入/删除值:触发 runtime.growWork 增量拷贝哈希表中的内容:
string
// 在运行时都会使用如下的 reflect.StringHeader 表示
type StringHeader struct {
Data uintptr
Len int
}
字符串是一个只读的切片类型。所有在字符串上的写入操作都是通过拷贝实现的。
反引号声明的字符串在遇到需要手写 JSON 的场景下非常方便
json := `{"author": "draven", "tags": ["golang"]}`
字符串拼接
使用 + 符号调用了 addstr 函数:
- 如果字符串数量小于或者等于 5 个,那么会调用 concatstring{2,3,4,5} 等一系列函数;最终调用 runtime.concatstrings
- 如果超过 5 个,那么会选择 runtime.concatstrings 传入一个数组切片;
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
if n == 0 {
continue
}
l += n
count++
idx = i
}
if count == 0 {
return ""
}
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
s, b := rawstringtmp(buf, l)
for _, x := range a {
copy(b, x)
b = b[len(x):]
}
return s
}
如果非空字符串的数量为 1 并且当前的字符串不在栈上,就可以直接返回该字符串,不需要做出额外操作
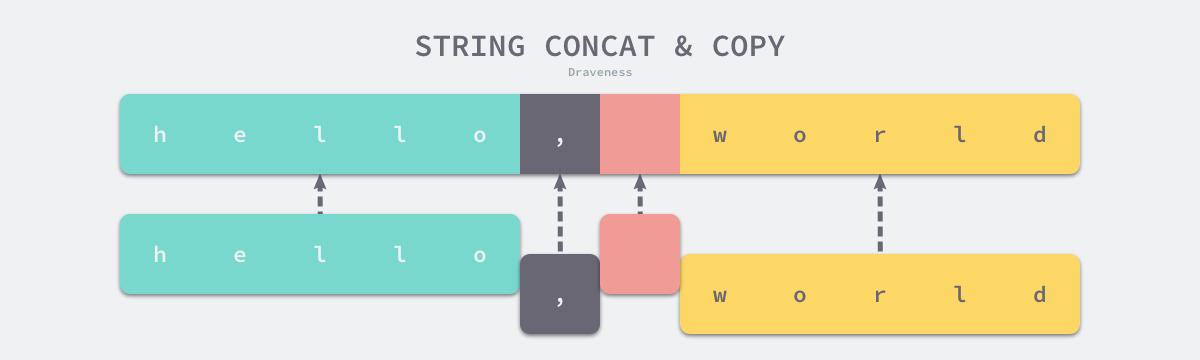
但正常情况下,运行时会调用 copy 将输入的多个字符串拷贝到目标字符串所在的内存空间。新的字符串是一片新的内存空间,与原来的字符串也没有任何关联,一旦需要拼接的字符串非常大,拷贝带来的性能损失是无法忽略的。
类型转换
string 和 []byte 之间的转换:
- string(bytes): 使用 runtime.slicebytetostring 函数:先处理两种比较常见的情况,也就是长度为 0 或者 1 的字节数组;处理过后会根据传入的缓冲区大小决定是否需要为新字符串分配一片内存空间,最后通过 runtime.memmove 将原 []byte 中的字节全部复制到新的内存空间中。
- string to []byte: 使用 runtime.stringtoslicebyte 函数:
- 当传入缓冲区时,它会使用传入的缓冲区存储 []byte;
- 当没有传入缓冲区时,运行时会调用 runtime.rawbyteslice 创建新的字节切片并将字符串中的内容拷贝过去;
string 小结
在做拼接和类型转换等操作时一定要注意性能的损耗,遇到需要极致性能的场景一定要尽量减少类型转换的次数。
function call
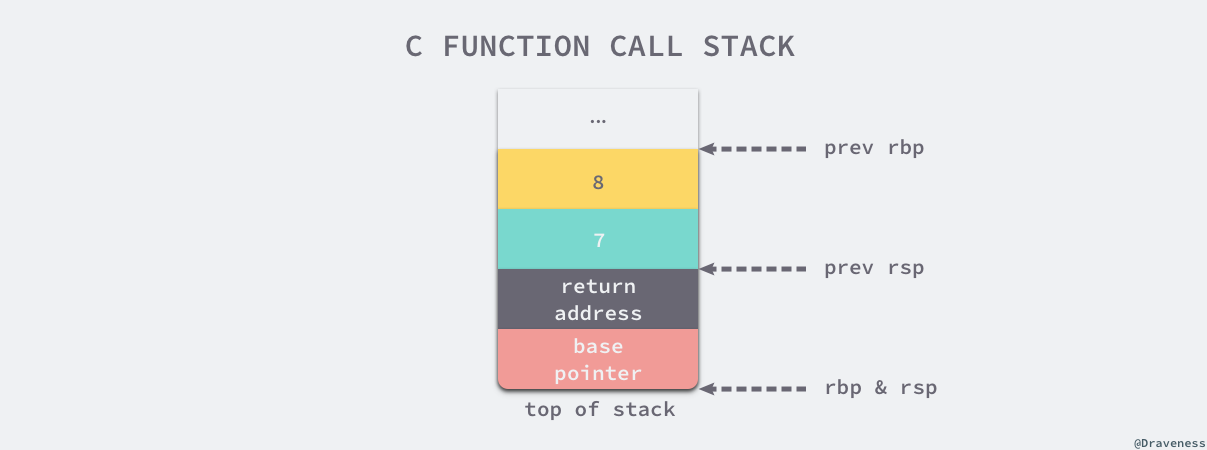
- 六个以及六个以下的参数会按照顺序分别使用 edi、esi、edx、ecx、r8d 和 r9d 六个寄存器传递;
- 六个以上的参数会使用栈传递,函数的参数会以从右到左的顺序依次存入栈中;
而函数的返回值是通过 eax 寄存器进行传递的,由于只使用一个寄存器存储返回值,所以 C 语言的函数不能同时返回多个值。

- CPU 访问栈的开销比访问寄存器高几十倍;
- C 需要单独处理函数参数过多的情况;
- Go 不需要考虑超过寄存器数量的参数应该如何传递;
- Go 不需要考虑不同架构上的寄存器差异;
- Go 函数入参和出参的内存空间需要在栈上进行分配;
参数传递
Go 语言选择了传值的方式,无论是传递基本类型、结构体还是指针,都会对传递的参数进行拷贝
接口
Go 在接口中我们只能定义方法签名,不能包含成员变量. 接口的实现都是隐式的
type error interface {
Error() string
}
| 结构体实现接口 | 结构体指针实现接口 | |
|---|---|---|
| 结构体初始化变量 | 通过 | 不通过 |
| 结构体指针初始化变量 | 通过 | 通过 |
type Cat struct {}
type Duck interface { ... }
func (c Cat) Quack {} // 使用结构体实现接口
func (c *Cat) Quack {} // 使用结构体指针实现接口
var d Duck = Cat{} // 使用结构体初始化变量
var d Duck = &Cat{} // 使用结构体指针初始化变量
方法的接受者是结构体,而初始化的变量是结构体指针之所以可以:作为指针的 &Cat{} 变量能够隐式地获取到指向的结构体
Go 语言的接口类型不是任意类型
package main
type TestStruct struct{}
func NilOrNot(v interface{}) bool {
return v == nil
}
func main() {
var s *TestStruct
fmt.Println(s == nil) // #=> true
fmt.Println(NilOrNot(s)) // #=> false
}
原因: 调用 NilOrNot 函数时发生了隐式类型转换,转换后的变量不仅包含转换前的变量,还包含变量的类型信息 TestStruct
数据结构
- 不包含任何方法的 interface{} 类型 eface:只包含指向底层数据和类型的两个指针。所以 Go 语言的任意类型都可以转换成 interface{}
type eface struct { // 16 字节 _type *_type data unsafe.Pointer } - runtime.iface:
type iface struct { // 16 字节 tab *itab data unsafe.Pointer }
itab 和 _type 的区别:
- _type: Go 语言类型的运行时表示,包含类型的大小、哈希、对齐以及种类等。
- itab 32 字节,包含用于动态派发的虚函数表 fun [1]uintptr
使用结构体实现接口带来的开销会大于使用指针实现,而动态派发在结构体上的表现非常差,这也提醒我们应当尽量避免使用结构体类型实现接口。
reflect
反射修改变量:
func main() {
i := 1
v := reflect.ValueOf(&i)
v.Elem().SetInt(10)
fmt.Println(i)
}
$ go run reflect.go
10