Rust Concurrency
use std::thread;
fn main() {
// pass a closure
let numbers = vec![1, 2, 3];
thread::spawn(move || {
for n in numbers {
println!("{n}");
}
}).join().unwrap();
let t1 = thread::spawn(f);
println!("Hello from the main thread.");
t1.join().unwrap();
}
fn f(){
println!("Hello from another thread!");
let id = thread::current().id();
println!("This is my thread id: {id:?}");
}
// scoped thread
// scoped threads can borrow non-static data,
// as the scope guarantees all threads will be joined at the end
use std::thread;
fn main() {
let numbers = vec![1, 2, 3];
// argument s of the closure represents the scope.
thread::scope(|s| {
s.spawn(|| {
println!("length: {}", numbers.len());
});
s.spawn(|| {
for n in &numbers {
println!("{n}");
}
});
});
}
// interior mutability
// Cell<T> and RefCell<T> types may be mutated through shared references
// Both single threaded
// Cell implements interior mutability by moving values in and out of the Cell<T>.
// To avoid undefined behavior, it only allows you
// to copy the value out (if T is Copy),
// or replace it with another value as a whole
use std::cell::Cell;
fn f(v: &Cell<Vec<i32>>) {
let mut v2 = v.take(); // Replaces the contents of the Cell with an empty Vec
v2.push(1);
v.set(v2); // Put the modified Vec back
}
fn main() {
let v = Cell::new(vec![1, 2, 3]);
f(&v);
assert_eq!(v.into_inner(), vec![1, 2, 3, 1]);
}
// RefCell let you use references instead of values
// allow you to borrow its contents
// If you try to borrow it while it is already mutably borrowed it will panic.
fn f(v: &RefCell<Vec<i32>>) {
v.borrow_mut().push(1); // We can modify the `Vec` directly.
}
// When to choose interior mutability
// 1. Introducing mutability 'inside' of something immutable: Rc<RefCell<T>>
// 2. Implementation details of logically-immutable methods.
// 3. Mutating implementations of Clone
// RwLock & mutex: concurrent version of RefCell
// unlike a RefCell, it does not panic.
// Instead, it blocks the current thread — putting it to sleep when conflicting.
// more complicated version of mutex. Instead of a single lock() method,
// it has a read() and write() method for locking
// Atomics: concurrent version of Cell
// Unlike a Cell, they cannot be of arbitrary size.
// no generic Atomic<T> type for any T
// there are only specific atomic types such as AtomicU32 and AtomicPtr<T>.
// UnsafeCell: primitive building block for interior mutability.
// its get() method just gives a raw pointer to the value it wraps
// Usually UnsafeCell is not used directly, but wrapped in Cell or Mutex
// Send & Sync
// A type is Send if it can be sent to another thread.
// A type is Sync if it can be shared with another thread aka: &T is Send.
// They are auto traits. To opt out, add a field like std::marker::PhantomData<T>.
// PhantomData is treated as a T. not exist at runtime. zero-sized
use std::marker::PhantomData;
struct X {
handle: i32,
// Since Cell<()> is not Sync.
_not_sync: PhantomData<Cell<()>>,
}
// Raw pointers (*const T and *mut T) are neither Send nor Sync.
// To opt in Send & Sync, impl it urself
// Mutex<T> does not have an unlock() method.
// Instead lock() method returns MutexGuard.
// MutexGuard behaves like an exclusive reference through the DerefMut trait.
use std::sync::Mutex;
use std::thread;
fn main() {
let n = Mutex::new(0);
thread::scope(|s| {
for _ in 0..10 {
s.spawn(|| {
// MutexGuard. unwrap() relate to lock poisoning.
let mut guard = n.lock().unwrap();
for _ in 0..100 {
// DerefMut trait
*guard += 1;
}
});
}
});
// into_inner takes ownership of the mutex,
// nothing else have a reference to the mutex anymore
assert_eq!(n.into_inner().unwrap(), 1000);
}
// Lock Poisoning
// A Mutex gets marked as poisoned when a thread panics while holding the lock.
// When poisoned, the Mutex will no longer be locked,
// calling lock() will result in an Err.
// Lifetime of the MutexGuard:
// Any temporaries produced within a larger expression,
// like the guard returned by lock()
// will be dropped at the end of the statement.
list.lock().unwrap().push(1);
// common pitfall regarding to this:
// When using match, if let, or while let
// the lock is hold until the end of the block
if let Some(item) = list.lock().unwrap().front() {
process_item(item);
}
// This is OK
if list.lock().unwrap().pop() == Some(1) {
do_something();
}
// This is OK
let item = list.lock().unwrap().pop();
if let Some(item) = item {
process_item(item);
}
// Waiting: Parking and Condition Variables
// When data is mutated by multiple threads, there are many
// situations where they would need to wait for some event,
// for some condition about the data to become true.
// For example, if we have a mutex protecting a Vec,
// we might want to wait until it contains anything.
// If a mutex was all we had, we’d have to keep locking the mutex to
// repeatedly check if there’s anything in the Vec yet.
use std::collections::VecDeque;
use std::sync::Mutex;
use std::thread;
use std::time::Duration;
fn main() {
let queue = Mutex::new(VecDeque::new());
thread::scope(|s| {
// Consuming thread
let t = s.spawn(|| loop {
let item = queue.lock().unwrap().pop_front();
// if not found, park itself
if let Some(item) = item {
dbg!(item);
} else {
thread::park();
}
});
// Producing thread
for i in 0.. {
queue.lock().unwrap().push_back(i);
// wake it up
t.thread().unpark();
thread::sleep(Duration::from_secs(1));
}
});
}
// An important observation: this program would
// still be correct if we remove parking although inefficient.
// spurious wake-ups
// a call to unpark() before the thread parks itself does not get lost.
// Otherwise starve
// but unpark() requests don’t stack up
// Why condition variables:
// if we had multiple consumer threads taking items from the same queue,
// we need Condition Variables
use std::collections::VecDeque;
use std::sync::Condvar;
use std::sync::Mutex;
use std::thread;
use std::time::Duration;
fn main() {
let queue = Mutex::new(VecDeque::new());
let not_empty = Condvar::new();
thread::scope(|s| {
s.spawn(|| {
loop {
let mut q = queue.lock().unwrap();
let item = loop {
if let Some(item) = q.pop_front() {
break item;
} else {
// atomically unlock the mutex and start waiting
// wait() unlocks and sleep, when woken up,
// it relocks the mutex and returns a new MutexGuard
q = not_empty.wait(q).unwrap();
}
};
drop(q);
dbg!(item);
}
});
for i in 0.. {
queue.lock().unwrap().push_back(i);
not_empty.notify_one();
thread::sleep(Duration::from_secs(1));
}
});
}
// Normally, a Condvar is only ever used together with a single Mutex
// A downside of a Condvar is that it only works when used together with a Mutex.
Atomic Operations
// 探讨原子操作之前,需要看内存顺序 memory ordering,
// 每个原子操作都有一个std::sync::atomic::Ordering参数
// Relaxed:Still guarantees consistency on a single atomic variable,
// but does not promise anything about the relative order of operations
// between different variables.
// So two threads might see operations on different variables
// happen in a different order.
// Atomic Load and Store Operations
impl AtomicI32 {
pub fn load(&self, ordering: Ordering) -> i32;
// only takes shared reference
pub fn store(&self, value: i32, ordering: Ordering);
}
// std::sync::Once and std::sync::OnceLock
// A cell which can be written to only once
pub struct OnceCell<T> { /* private fields */ }
// thread-safe OnceCell, can be used in statics.
// 用get_or_init获取值
pub struct OnceLock<T>
// Fetch-and-Modify Operations
// could overflow compared to CAS
// Example: Progress Reporting from Multiple Threads
// https://github.com/m-ou-se/rust-atomics-and-locks/blob/main/examples/ch2-06-progress-reporting-multiple-threads.rs
// example: Statistics
// the three atomic variables are updated separately,
// the Relaxed memory ordering gives no guarantees about the relative order of operations
// https://github.com/m-ou-se/rust-atomics-and-locks/blob/main/examples/ch2-07-statistics.rs
// example: ID Allocation. could overflow
// https://github.com/m-ou-se/rust-atomics-and-locks/blob/main/examples/ch2-08-id-allocation.rs
// CAS signature
impl AtomicI32 {
pub fn compare_exchange(
&self,
expected: i32,
new: i32,
success_order: Ordering,
failure_order: Ordering
) -> Result<i32, i32>;
}
// CAS example usage
use std::sync::atomic::AtomicU32;
use std::sync::atomic::Ordering::Relaxed;
fn increment(a: &AtomicU32) {
let mut current = a.load(Relaxed);
loop {
let new = current + 1;
match a.compare_exchange(current, new, Relaxed, Relaxed) {
Ok(_) => return,
Err(v) => current = v,
}
}
}
fn main() {
let a = AtomicU32::new(0);
increment(&a);
increment(&a);
assert_eq!(a.into_inner(), 2);
}
// compare_exchange_weak is more efficiently on some platforms.
// Fetch-Update: for the compare-and-exchange loop pattern.
// CAS 的应用场景:生成某种密钥,只要生成一次,之后的就不要再生成了,用已经有的
use std::sync::atomic::AtomicU64;
use std::sync::atomic::Ordering::Relaxed;
fn get_key() -> u64 {
static KEY: AtomicU64 = AtomicU64::new(0);
let key = KEY.load(Relaxed);
if key == 0 {
let new_key = generate_random_key();
match KEY.compare_exchange(0, new_key, Relaxed, Relaxed) {
Ok(_) => new_key,
Err(k) => k,
}
} else {
key
}
}
fn generate_random_key() -> u64 {
123
}
// Memory Reordering
Ordering::Relaxed
Ordering::{Release, Acquire, AcqRel}
Ordering::SeqCst
// ?????? output could be 0 20
static X: AtomicI32 = AtomicI32::new(0);
static Y: AtomicI32 = AtomicI32::new(0);
fn a() {
X.store(10, Relaxed);
Y.store(20, Relaxed);
}
fn b() {
let y = Y.load(Relaxed);
let x = X.load(Relaxed);
println!("{x} {y}");
}
fn main() {
thread::scope(|s| {
s.spawn(a);
s.spawn(b);
});
}
// Spawning and Joining
// Spawning a thread creates a happens-before relationship
// between what happened before the spawn() call, and the new thread.
// Similarly, joining a thread creates a happens-before relationship
// between the joined thread and what happens after the join() call.
// 也就是只有中间的部分能上下移动
Relaxed Ordering
While atomic operations using relaxed memory ordering do not provide any happens-before relationship, they do guarantee a total modification order of each individual atomic variable. This means that all modifications of the same atomic variable happen in an order that is the same from the perspective of every single thread. 在不同的线程看来,对于同一个原子变量的不同修改是相同顺序的 reference code: https://github.com/m-ou-se/rust-atomics-and-locks/blob/main/examples/ch3-04-total-modification-order-2.rs
Release and Acquire Ordering
Release and acquire memory ordering are used in a pair to form a happens-before relationship between threads. Release memory ordering applies to store operations, while Acquire memory ordering applies to load operations. 当acquire-load operation 观察到 release-store operation 的结果的时候,A happens-before relationship is formed。store及之前的 happened before load及之后的 (like Spawning and Joining) When using Acquire for a fetch-and-modify or compare-and-exchange operation, it applies only to the part of the operation that loads the value. Similarly, Release applies only to the store part of an operation. AcqRel is used to represent the combination of Acquire and Release, which causes both the load to use acquire ordering, and the store to use release ordering code:https://github.com/m-ou-se/rust-atomics-and-locks/blob/main/examples/ch3-06-release-acquire.rs 结果只可能是123。如果用Relaxed内存顺序的话,就可能是0了 所以 release 和 acquire 是成对出现的,用来建立 happens before 关系的 在上面这个code的例子中,happens-before relationship的存在导致我们其实不需要这些操作是原子的也不会store 和 load 同时发生。但我们换成 non-atomic type 的话 Rust 的类型系统不理解,所以要unsafe
如果acquire-load 对应的 release 是个 fetch-and-modify 或者compare-and-exchange 操作而不是普通store操作,那这个load和之前任意个 fetch-and-modify 或者compare-and-exchange 操作都形成了happens before关系
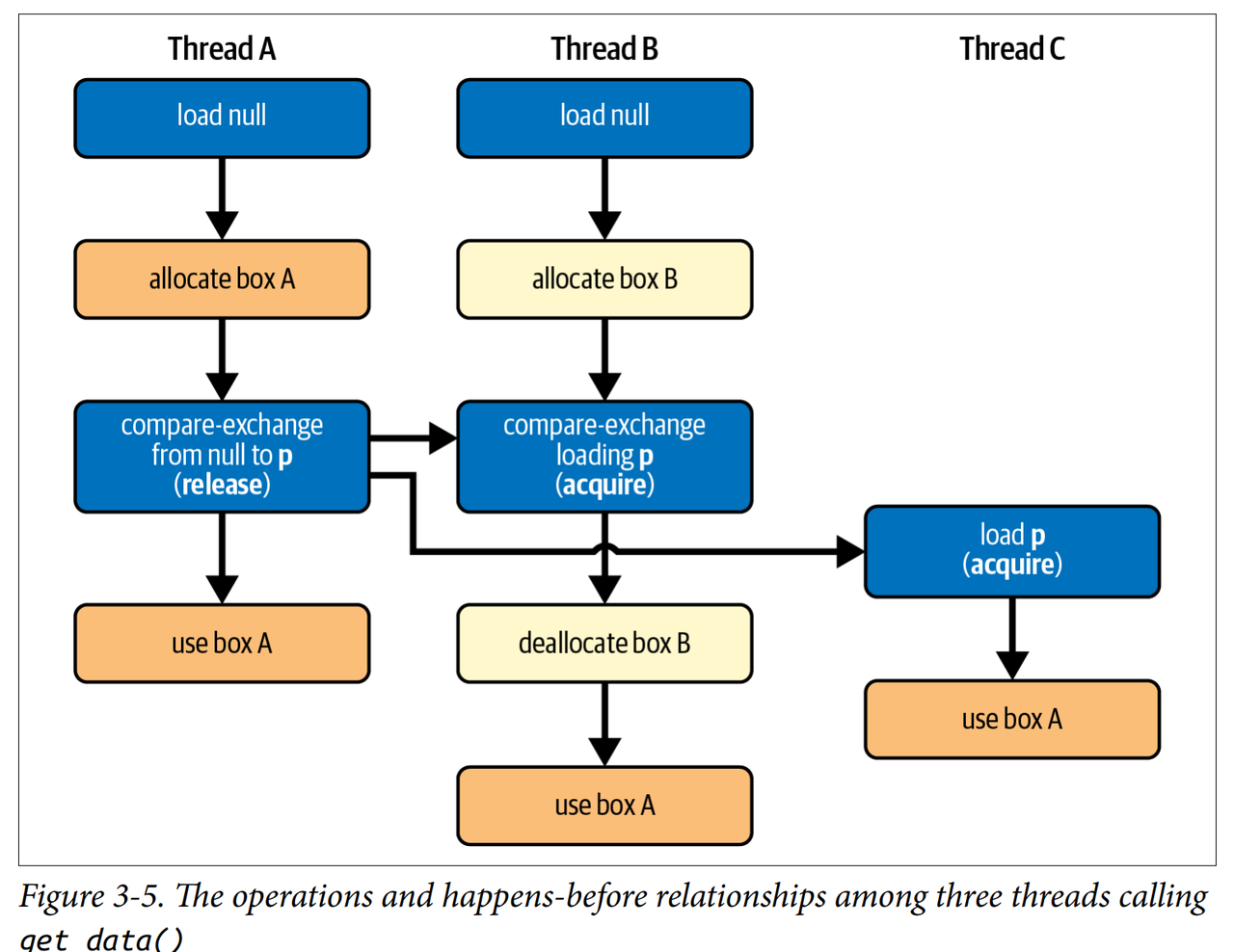
we use release and acquire memory ordering to make sure initializing the data has actually happened-before creating a reference to it code:https://github.com/m-ou-se/rust-atomics-and-locks/blob/main/examples/ch3-09-lazy-init-box.rs
Consume Ordering
Something weaker than acquire ordering might suffice: consume ordering. more efficient but hard to implement. For now, unfeasible.
Sequentially Consistent Ordering
The strongest memory ordering: Ordering::SeqCst almost never necessary
Memory Ordering Summary
- There might not be a global consistent order of all atomic operations, as things can appear to happen in a different order from different threads.
- However, each individual atomic variable has its own total modification order, regardless of memory ordering, which all threads agree on.
- The order of operations is formally defined through happens-before relationships.
- Within a single thread, there is a happens-before relationship between every single operation.
- Spawning a thread happens-before everything the spawned thread does.
- Everything a thread does happens-before joining that thread.
- Unlocking a mutex happens-before locking that mutex again.
- Acquire-loading the value from a release-store establishes a happens-before rela‐ tionship. This value may be modified by any number of fetch-and-modify and compare-and-exchange operations.
- A consume-load would be a lightweight version of an acquire-load, if it existed.
- Sequentially consistent ordering results in a globally consistent order of opera‐ tions, but is almost never necessary and can make code review more complicated.
- Fences allow you to combine the memory ordering of multiple operations or apply a memory ordering conditionally.
try impl
my_spin_lock: https://github.com/m-ou-se/rust-atomics-and-locks/blob/main/src/ch4_spin_lock/s3_guard.rs
My_channels: https://github.com/m-ou-se/rust-atomics-and-locks/blob/main/src/ch5_channels/s6_blocking.rs